从仓库里的物流机器人到科幻电影中的「贾维斯」,我们对智能机器人的想象从未停止。学术界在模拟器里实现了越来越复杂的协作任务,工业界也让机器人学会了韦伯斯特空翻。
然而,一个残酷的现实是:当下的机器「人」更像是提线木偶,而非真正自主的智能体。
想象一下,机器人每做一个动作都要延迟十几秒,完成同样的任务比人类慢上十倍,这样的效率如何走入我们的生活?这个从虚拟到现实的「最后一公里」,其瓶颈常常被忽视:高昂的时间延迟和低下的协作效率。它像一道无形的墙,将真正的具身智能困在了实验室里。

为了打破这一僵局,来自佐治亚理工学院、明尼苏达大学和哈佛大学的研究团队将目光从单纯的「成功」转向了「成功且高效」。他们推出了名为 ReCA 的集成加速框架,针对多机协作具身系统,通过软硬件协同设计跨层次优化,旨在保证不影响任务成功率的前提下,提升实时性能和系统效率,为具身智能落地奠定基础。
简单来说:ReCA 不再满足于让智能体「完成」任务,而是要让它们「实时、高效地完成」任务。
这份工作发表于计算机体系结构领域的顶级会议 ASPLOS'25,是体系结构领域接收的首批具身智能计算论文,同时入选 Industry-Academia Partnership (IAP) Highlight。
三大瓶颈:
当前模块化具身智能的「效率之殇」
研究团队首先对当前的协同具身智能系统(如 COELA, COMBO, MindAgent)进行了系统性分析,定位了三大性能瓶颈:
高昂的规划与通信延迟: 系统严重依赖基于 LLM 的模块进行高阶规划和智能体间通信。每一步行动都可能涉及多次 LLM 的顺序调用,其中网络延迟和 API 调用成本更是雪上加霜,使得实时交互成为奢望。
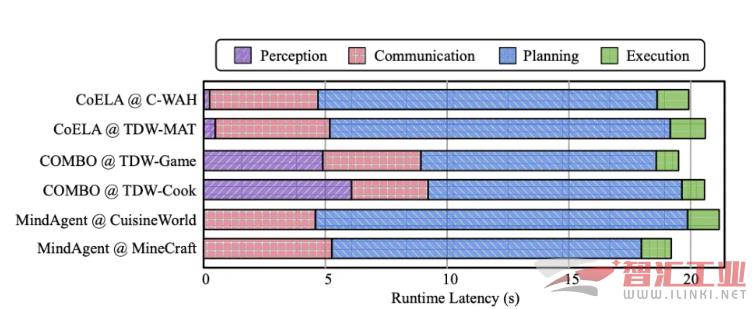
有限的可扩展性: 随着智能体数量的增加,去中心化系统会面临通信轮次爆炸性增长和效率下降的问题;而中心化系统则由于单一规划者难以处理复杂的多智能体协同,导致任务成功率急剧下滑。
底层执行的敏感性: LLM 生成的高阶计划需要被精确翻译成底层的控制指令,底层执行的效率和鲁棒性直接关系到任务的成败。
ReCA 的「三板斧」:
从算法到系统再到硬件的跨层协同优化
针对上述挑战,ReCA 提出了一个贯穿算法、系统和硬件三个层面的跨层次协同设计框架,旨在提升协同具身智能系统的效率和可扩展性。
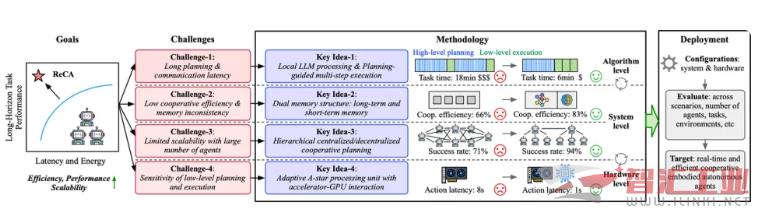
算法层面:更聪明的规划与执行
本地化模型处理: 通过部署更小的、本地化的经过微调的开源 LLM,ReCA 摆脱了对外部 API 的依赖,消除了网络延迟瓶颈,同时保障了数据隐私。
规划指导下的多步执行: 颠覆了传统「规划一步、执行一步」的模式。ReCA 让 LLM 一次性生成可指导连续多步底层动作的高阶计划,大幅减少了 LLM 的调用频率,显著降低了端到端延迟。
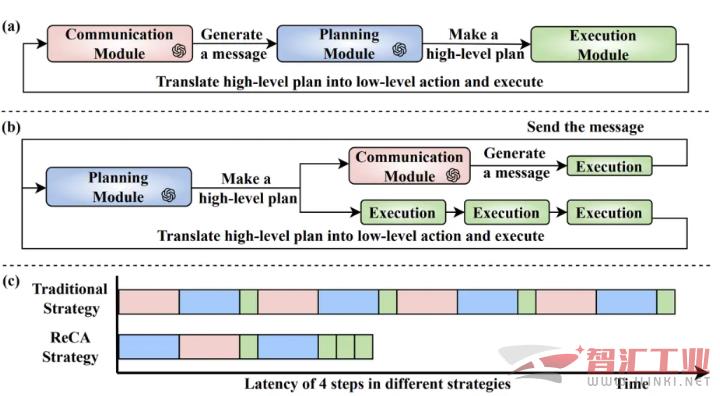
系统层面:更高效的记忆与协作
双重记忆结构: 借鉴了人类认知的「双系统理论」,ReCA 设计了长短时记忆分离的结构。
长期记忆以图结构存储环境布局等静态信息。
短期记忆则动态刷新智能体状态、任务进度等实时信息。
有效解决了 LLM 在长任务中 prompt 过长导致「遗忘」关键信息的痛点,提升了规划的连贯性和准确性。
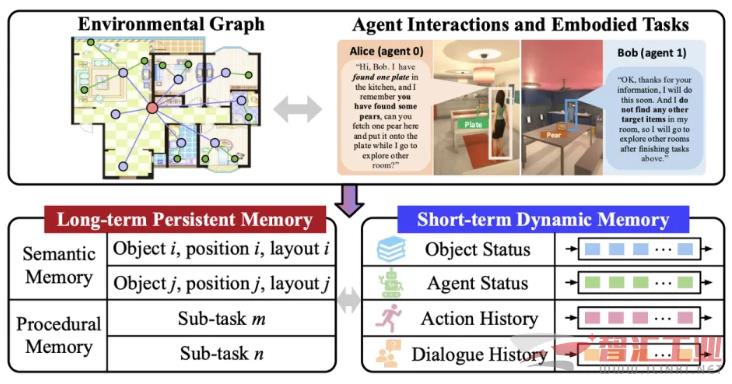
分层协作规划: 为了解决扩展性难题,ReCA 引入了一种新颖的分层协作模式。在小范围的「簇」内,采用「父-子」智能体的中心化模式高效规划;在「簇」之间,则采用去中心化模式进行通信,更新彼此进度。这种混合模式兼顾了规划效率和系统规模。
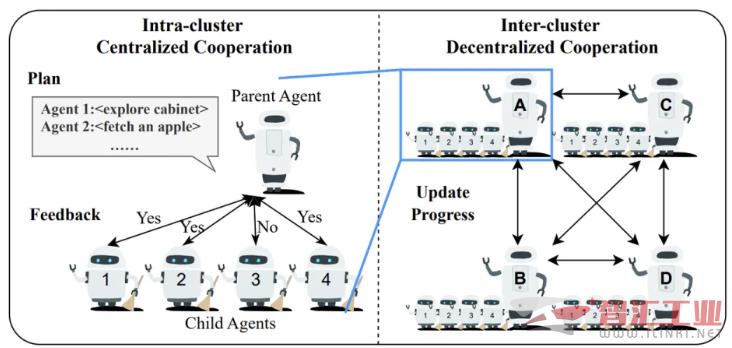
硬件层面:更专业的加速单元
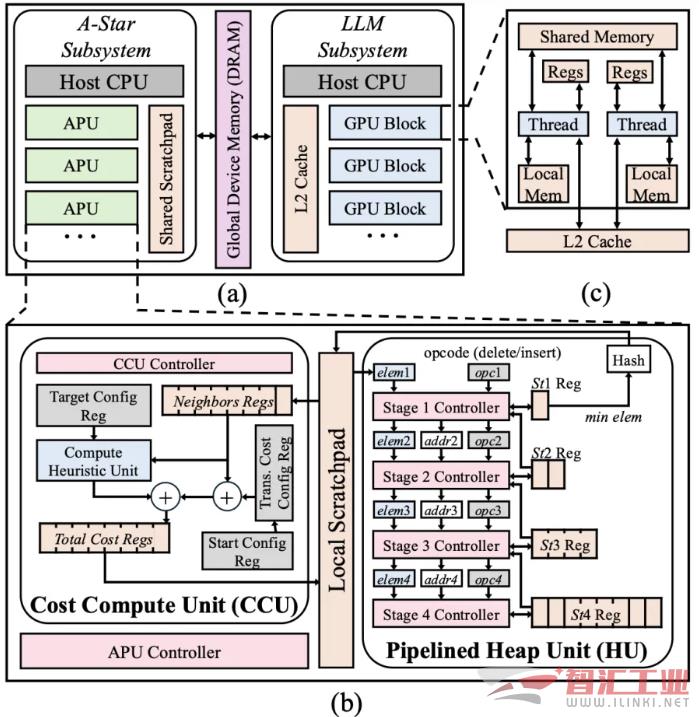
异构硬件系统: ReCA 为高阶和低阶规划匹配了最合适的计算单元。它采用 GPU 子系统处理 LLM 的高阶规划,同时为精准路径规划等低阶任务设计了专门的硬件加速器。
专用路径规划处理器: 研究表明,在系统优化后,原本占比不高的 A-star 路径规划延迟会成为新的瓶颈。ReCA 的专用 A-Star Processing Unit(APU)通过定制化的计算单元和访存设计,大幅提升了低阶规划的效率和能效。
效率提升:
5-10 倍速度提升,成功率不降反升
通过跨越六个基准测试和三大主流协同系统的评估,ReCA 展现了其强大的实力:
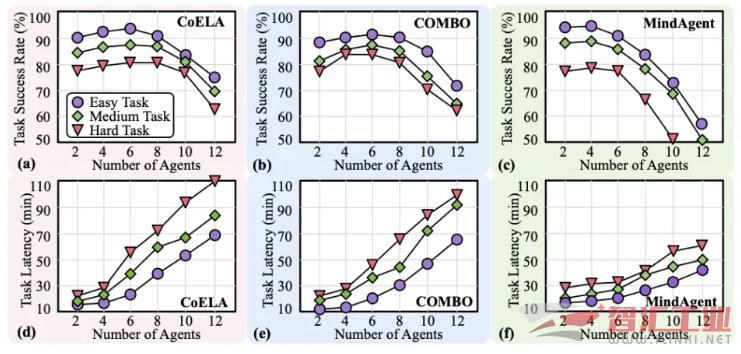
效率: 在任务步骤仅增加 3.2% 的情况下,实现了平均 5-10 倍的端到端任务加速。原本需要近一小时的复杂任务,ReCA 能在 20 分钟内完成。
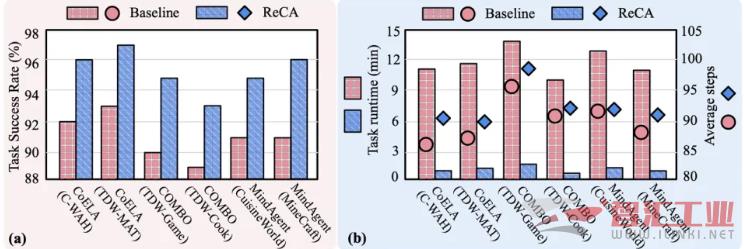
成功率: 在大幅提升速度的同时,任务成功率平均还提升了 4.3%。这得益于其优化的记忆和协作机制,证明了效率与性能可以兼得。
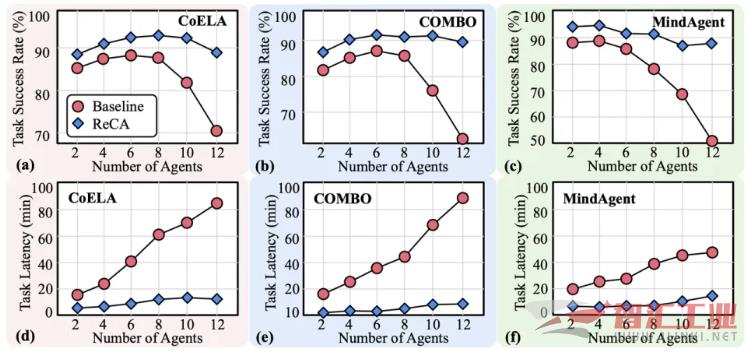
可扩展性: 即使在 12 个智能体的大规模协作场景下,ReCA 依然能保持 80-90% 的高成功率,而基线系统的成功率已跌至 70% 以下。
能效: 其定制的 A-star 硬件加速器(APU)相较于 GPU 实现,取得了 4.6 倍的速度提升和 281 倍能效改进。
ReCA 的意义,远不止于一组性能提升的数据。它更像一块基石,为具身智能的未来发展铺设了三条关键路径:
从「能用」到「好用」的跨越: 此前,研究的焦点大多是如何让机器人「成功」完成任务。ReCA 则明确地提出,「成功且高效」是更关键的目标。这项工作有助于推动领域的研究范式转变,让延迟、效率和可扩展性也成为衡量具身智能系统的核心指标,加速其在家庭服务、智能制造等场景的落地。
「软硬协同」释放效能提升: ReCA 通过算法、系统、硬件的跨层次协同优化,突破了过往「单点优化」的局限。未来的具身智能系统,有望像 ReCA 一样,在不同层面协同设计的产物。它为 GPU 处理高阶规划、硬件加速器处理底层精确任务的异构计算模式提供了范本,为下一代机器人「大脑」+「小脑」的设计提供了一种可行方案。
突破瓶颈,解锁想象力: 当延迟不再是瓶颈,我们可以大胆想象:一个机器人管家团队能在你下班前,实时协作,烹饪好一顿丰盛的晚餐,并打扫干净房间;又或者在灾难救援现场,多个机器人能实时共享信息,高效协同,在黄金救援时间内完成搜索与拯救任务。在自动化科学实验室里,机器人集群能够 7x24 小时不间断地进行复杂的协同实验,以前所未有的速度推动科学发现。
总而言之,ReCA 的工作不仅解决了一个关键的技术瓶颈,更是为具身智能从实验室走向真实世界,架起了一座坚实的桥梁。我们距离那个能实时响应、高效协作的「贾维斯」式智能助手,确实又近了一大步。